
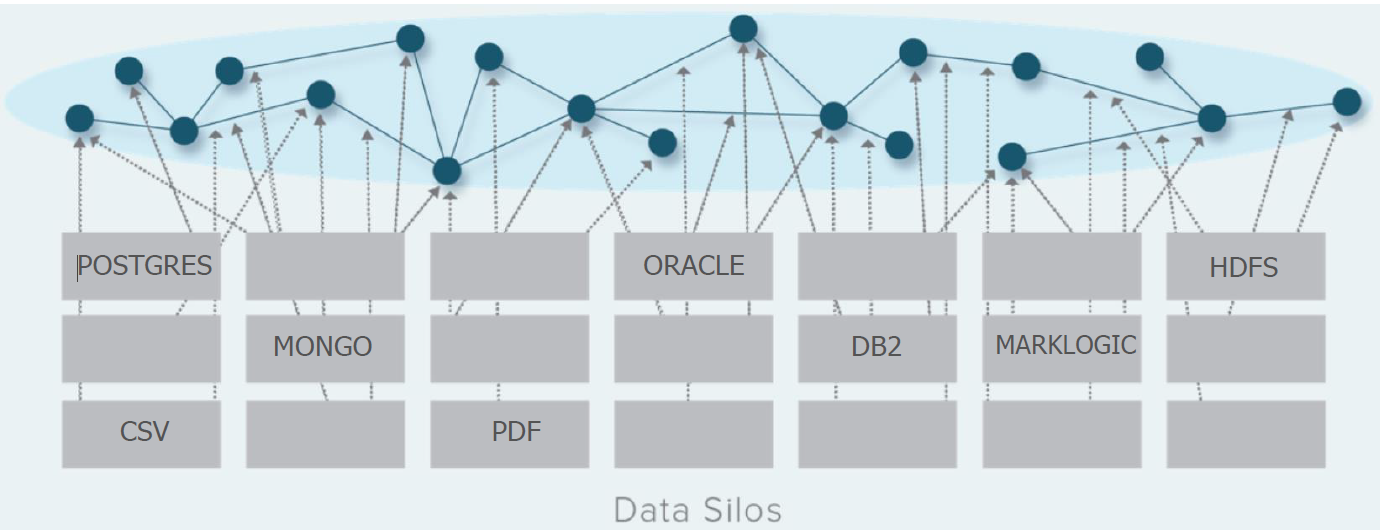
Au fil des années, les organisations ont accumulé dans leurs systèmes d’informations une multitude de données. Ces données auront permis à l’organisation d’opérer et de remplir leur mission au quotidien. Aujourd’hui, dans certains cas, ces données constituent un patrimoine d’informations que, s’ils étaient partagés avec d’autres unités ou départements, constituerait une plus-value pour l’organisation concernée. Ce besoin est aussi présent dans le contexte élargi: des villes intelligentes, de l’internet des objets, du big data, de l’intelligence d’affaires où l’échange de données constitue un enjeu fondamental.
Le partage des données et la problématique d’interopérabilité
Alors, quand vient le temps d’exposer ses données, un problème technologique majeur et complexe se pose. Comment interchanger des données entreposées dans des bases de données (BD) de technologies hétérogènes (par ex. : des données à échanger entre une BD Oracle et une BD MysSql). Bien qu’il existe des solutions pour résoudre ce problème, elles sont souvent complexes à implanter, à maintenir et elles sont rarement économiques.
Qu’est-ce qui occasionne le problème d’interopérabilité ?
En fait, le problème d’interopérabilité des données vient du fait que dans une BD classique, la donnée et le cadre qui la structure sont codés dans une notation propre et propriétaire au logiciel qui gère les données. Par exemple, la table des employés d’une entreprise ne sera pas entreposée de la même façon dans une BD Oracle et une BD MySql.
À l’instar des documents dans le web, il existe une technologie qui vise à inter-opérationnaliser la donnée, il s’agit du web sémantique
Le web sémantique est une solution d’interopérabilisation des données qui, comme les autres technologies du web, est normalisé par le W3C (World Wide Web Consortium). La technologie du web sémantique offre les dispositifs nécessaires à l’exploitation, la diffusion, la recherche dans les données interopérables. La donnée traitée par cette technologie est totalement découplée de l’architecture du logiciel qui la supporte. L’interopérabilité de la donnée du web sémantique fonctionne selon le même principe que la présentation de l’information dans le web. Un serveur web diffuse une page HTML et il n’a pas à se soucier de la technologie qui lira cette page. De même, le client web, qui est souvent un fureteur comme: FireFox, Safarie, Internet Explorer, etc. n’a pas à se soucier de la technologie qui dessert la page HTML. C’est exactement le même principe qui sous-tend l’interopérabilité des données dans le web sémantique.
Le dispositif langagier du web sémantique : l’URI, le RDF, le RDFS et l’ontologie qui sert à interopérationaliser la donnée
Par définition, tout ce qui est dans le web est considéré comme une Ressource, même une donnée. Comme pour une page web, dans le web sémantique, la ressource est identifiée par une Unified Ressource Indentifier (URI) (par exemple : http://cotechnoe.com/compagnie#MichelHeon). Il s’agit d’un identifiant unique dans le web. Quant au Resource Description Framework (RDF), il est un « framework » utilisé pour décrire une ressource, par exemple, indiquer un Michel est un Technicien. Finalement, le Resource Description Framework Schema (RDFS) est le dispositif langagier qui permet de définir la structure de donnée. L’équivalent de la définition des tables dans une BD. C’est avec le RDFS qu’il est possible de coder qu’un Technicien est une sorte d’Employé et qu’un Employé à la propriété d’avoir un statut temporaire ou permanent. C’est d’ailleurs par le dispositif RDF/RDFS que le web devient « sémantique ». Il existe d’autres dispositifs langagiers qui exploitent le RDF/RDFS pour étendre l’expressivité du langage que l’on nomme « ontologie » qui sert à exprimer des situations plus complexes. C’est le cas entre autres du Web Ontology Language (OWL), du Simple Knowledge Organization System (SKOS) et bien d’autres.
Exploiter l’interopérabilité des ontologies pour réutiliser la donné et éviter d’avoir à re-concevoir la structure des données
Nous avons vu avec les ontologies OWL et SKOS, qu’il existe des structures standardisées et interopérables qui permettent de structurer nos données dans le web. Du fait qu’il existe un dispositif interopérable de modélisation des données (les ontologies), alors on a vu apparaitre sur le web un nombre impressionnant d’initiatives de définitions de vocabulaires réutilisables (fondées sur RDF/RDFS) en fonction du domaine dans lequel on souhaite exploiter la donnée. Par exemple : l’ontologie FIBO pour le domaine de la finance, Dublin Core dans le domaine de l’édition, CIDOC pour la description de données culturelles, Friend Of a Friend pour les réseaux sociaux, et bien d’autres à découvrir. Ainsi, pour une solution maison, en plus de modéliser sa propre structure dans une ontologie, il est tout à fait possible d’agréger et exploiter les structures ontologiques déjà normalisées et disponibles sur le web. C’est à cette étape que le web de données ouvertes et liées (Linked Open Data -LOD-) fait son apparition. Mais ceci sera le sujet d’un autre billet…
Dispositif d’accès aux données diffusées à partir d’un serveur web : le SPARQL endpoint.
Comme tout système d’entrepôt de données, la technologie sémantique possède un dispositif de requêtes permettant d’extraire un sous-domaine de données en fonction de conditions spécifiques. Le langage de requête dévolue au web sémantique est le SPARQL (qui se prononce comme « étincelle » en anglais), qui est en fait l’acronyme de SPARQL Query Language for RDF. Il est possible d’accéder aux données diffusées par un serveur web via le web service SPARQL endpoint. L’URL du SPARQL endpoint est aussi normalisée sous la forme de « http://nomserveur/sparql ». Par exemple le SPARQL endpoint, de dbpedia, (l’entrepôt sémantique de données issues de Wikipédia) est le http://dbpedia.org/sparql. Lorsque vous entrez cette URL dans la barre d’adresse de votre fureteur web, apparait alors une page avec une commande. En cliquant « Run Query » vous activez la recherche sur le serveur et le résultat de cette recherche apparait dans la page.
Pour un néophyte, la réponse est quelque peu … occulte. Par contre, les données qui y sont présentées le sont dans un format interopérable et exploitable par un système d’informations distant, qui vise à réutiliser ces données pour éventuellement en générer de nouvelles (par la conjonction avec des données locales), et qui elles mêmes, peuvent être ré-exploitées, par exemple, dans le contexte d’un système d’intelligence d’affaires.
La technologie sémantique: avant tout, une solution d’interopérabilité des données, et pas obligatoirement une solution de diffusion des données sur le web
En raison de sa dénomination « web sémantique », on imagine souvent que cette technologie est dévolue à une solution web, au sens « grand public » du web. Néanmoins, ceci est un malentendu. En fait, la technologie sémantique peut tout à fait être déployée dans un intranet pour desservir des données privées dans un sous réseau sécurisé de la même manière que sont utilisées les pages d’informations dans les serveurs web intranet. À vrai dire, la technologie sémantique devient une solution dès lors qu’une problématique d’interopérabilité des données se pose.
Pourquoi les technologies du web sémantique doivent-elles avoir une place de choix dans l’évaluation d’une solution d’interopérabilisation des données ?
Les technologies du web sémantique sont mures, elles sont apparues vers les années 2001, elles ont donc à ce jour, plus de 15 ans d’âge. Elles sont aussi non-propriétaires (elles appartiennent à tous), elles sont normalisées et elles sont régies par un organisme sans but lucratif et international (le W3C) dont la mission est de définir, en partenariat avec les chercheurs et les grandes entreprises du monde entier, les standards technologiques du web. Finalement, pour cette technologie, la plupart des fournisseurs de solutions offrent des mécanismes qui permettent d’interfacer leur système propriétaire aux technologies sémantiques.
Oui… mais …
Bien sûr, il y a un prix à payer. Ce prix, c’est le changement de paradigme dans la représentation des données. L’administrateur de base de données conventionnel est familier avec une représentation des données dans un format du type Entité-Relation et la gestion d’enregistrements dans une Table. Or, avec la technologie sémantique, la forme de base de la représentation des données est l’Énoncé structuré en sujet-prédicat-objet qui est géré par des réseaux de graphes. De plus, l’idée selon laquelle la donnée est interopérable génère souvent de la confusion sur les possibilités de traitement de ces données. Ainsi, l’incorporation des technologies sémantiques impose un changement de paradigme profond chez les technologues, les gestionnaires et les utilisateurs qui utilisent ces données. Ce changement de paradigme peut causer des instabilités dans l’organisation s’il n’est pas mené avec un processus de gestion de changement adéquat incluant des professionnels compétant en la matière.
La question de performance est aussi une autre problématique à évaluer. Comme tous systèmes web, la technologie du web sémantique n’a pas le niveau de performances de traitement de l’information que l’on peut retrouver dans les solutions natives. Il importe donc de bien considérer et évaluer cet aspect avant la conception et la mise en œuvre de la solution.
En conclusion
Il a été présenté dans ce billet qu’il existe, par le biais des technologies du web sémantique, une solution pour le décloisonnement et l’échange des données qui sont actuellement en silos. Du point de vue technologique, le décloisonnement de la donnée passe par l’utilisation de dispositifs qui permettent d’interopérationaliser la donnée. La technologie du web sémantique offre ces dispositifs. Pour interopérationnaliser la donnée, il est aussi nécessaire d’interopérationnaliser la structure qui décrit la donnée. Les dispositifs langagiers qui servent à interopérationalisée les données sont l’URI, le RDF et le RDFS. Il existe une structure interopérable qui exploite l’URI-RDF/RDFS pour décrire des vocabulaires dévolus à des domaines spécifiques que l’on nomme Ontologie et qui sont réutilisables pour des solutions maisons. Pour exécuter des requêtes sur ces données, le langage SPARQL et son accès via le service web SPARQL endpoint permet d’accéder aux donnés entreposées dans le serveur web. Il est possible de tirer profit de la technologie sémantique est l’utilisant dans l’environnement du web mondial (le web de données ouvertes et liées) ou à l’abri dans un intranet privé. La technologie du web sémantique est normalisée, standardisée par le W3C et libre de droits d’accès et d’usage. Il faut cependant gérer son intégration dans l’organisation par le biais du mécanisme de gestion de changement adaptée et faire appel à des professionnels qualifiés.
Michel Héon PhD
Docteur en informatique cognitive
Président fondateur de Cotechnoe